 |
Eleven Metrics to Monitor for a Happy and Healthy Squidby Duane Wessels, author of Squid: The Definitive Guide03/25/2004 |
In this article, I'll show you how to stay on top of Squid's performance. If you follow this advice, you should be able to discover problems before your users begin calling you to complain.
Squid provides two interfaces for monitoring its operation: SNMP and the cache manager. Each has its own set of advantages and shortcomings.
SNMP is nice because it is familiar to many of us. If you already have some
SNMP software deployed in your network, you may be able to easily add Squid to
the other services that you already monitor. Squid's SNMP implementation is
disabled by default at compile time. To use SNMP, you must pass the
--enable-snmp option to ./configure like this:
./configure --enable-snmp ...
The downside to SNMP is that you can't use it to monitor all of the metrics that I talk about in this article. Squid's MIB has remained almost unchanged since it was first written in 1997. Some of the things that you should monitor are only available through the cache manager interface.
The cache manager is a set of "pages" that you can request from Squid with a
special URL syntax. You can also use Squid's cachemgr.cgi utility
to view the information through a web browser. As you'll see in the examples, it
is a little awkward to use the cache manager for periodic data collection. I
have a solution to this problem, which I'll describe at the end of the
article.
|
Related Reading 
|
Squid's process size has a direct impact on performance. If the process becomes too large, and won't fit entirely in memory, your operating system swaps portions of it to disk. This causes performance to degrade quickly -- i.e., you'll see an increase in response times. Squid's process size can be a little bit difficult to control at times. It depends on the number of objects in your cache, the number of simultaneous users, and the types of objects that they download.
Squid has four ways to determine its process size. One or more of them may
not be supported on your particular operating system. They are:
getrusage(), mallinfo(), mstats(), and
sbrk().
The getrusage() function reports the "Maximum Resident Set Size"
(Max RSS). This is the largest amount of physical memory that the process has
ever occupied. This is not always the best metric, because if the process size
becomes larger than your memory's capacity, the Max RSS value does not increase.
In other words, Max RSS is always less than your physical memory size, no matter
how big the Squid process becomes.
The mallinfo() and mstats() functions are features
of some malloc (memory allocation) libraries. They are a good indication of
process size, when available. The mstats() function is unique to
the GNUmalloc library.
The sbrk() function also provides a good indication of process
size and seems to work on most operating systems.
Unfortunately, the only metric available as an SNMP object is the
getrusage() Max RSS value. You can get it with this OID under the
Squid MIB:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheMaxResSize
To get the other process size metrics, you'll need to use the cache manager. Request the "info" page and look for these lines:
# squidclient mgr:info | less
...
Process Data Segment Size via sbrk(): 959398 KB
Maximum Resident Size: 924516 KB
...
Total space in arena: 959392 KBYou can also use the high_memory_warning directive in
squid.conf to warn you if the process size exceeds a limit that you
specify. For example:
high_memory_warning 500As I mentioned in the discussion about memory usage, Squid's performance suffers when the process size exceeds your system's physical memory capacity. A good way to detect this is by monitoring the process' page-fault rate.
A page fault occurs when the program needs to access an area of memory that was swapped to disk. Page faults are blocking operations. That is, the process pauses until the memory area has been read back from disk. Until then, Squid cannot do any useful work. A low page-fault rate, say, less than one per second, may not be noticeable. However, as the rate increases, client requests take longer and longer to complete.
When using SNMP, Squid only reports the page-fault counter, rather than the
rate. The counter is an ever-increasing value reported by the
getrusage() function. You can calculate the rate by comparing
values taken at different times. Programs such as RRDTool and MRTG do this
automatically. You can get the page fault count by requesting this SNMP OID:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheSysPageFaults
Alternatively, you can get it from the cache manager's info page:
# squidclient mgr:info | grep 'Page faults'
Page faults with physical i/o: 2712You can also get the rate, calculated over five- and 60-minute intervals, by requesting other cache manager pages:
# squidclient mgr:5min | grep page_fault
page_faults = 0.146658/sec
# squidclient mgr:60min | grep page_fault
page_faults = 0.041663/secThe high_page_fault_warning directive in squid.conf
will warn you if Squid detects a high page fault rate. You specify a limit on
the mean page-fault rate, measured over a one-minute interval. For example:
high_page_fault_warning 10The HTTP request rate is a simple metric. It is the rate of requests made by clients to Squid. A quick glance at a graph of request rate versus time can help answer a number of questions. For example, if you notice that Squid suddenly seems slow, you can determine whether or not it is due to an increase in load. If the request rate seems normal, then the slowness must be due to something else.
Once you get to know what your daily load pattern looks like, you can easily identify strange events that may warrant further investigation. For example, a sudden drop in load may indicate some sort of network outage, or perhaps disgruntled users who have figured out how to bypass Squid. Similarly, a sudden increase in load might mean that one or more of your users has installed a web crawler or has been infected with a virus.
As with the page fault value, you can only get the HTTP request counter value from SNMP. Use this OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheProtoAggregateStats.cacheProtoClientHttpRequests
The cache manager reports this information in a variety of ways:
# squidclient mgr:info | grep 'Number of HTTP requests'
Number of HTTP requests received: 535805
# squidclient mgr:info | grep 'Average HTTP requests'
Average HTTP requests per minute since start: 108.4
# squidclient mgr:5min | grep 'client_http.requests'
client_http.requests = 3.002991/sec
# squidclient mgr:60min | grep 'client_http.requests'
client_http.requests = 2.636987/secIf you have neighbor caches using ICP, you'll probably want to monitor the ICP request rate as well. While there aren't any significant performance issues related to ICP queries, this will at least tell you if neighbor caches are up and running.
To get the ICP query rate via SNMP, use this OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheProtoAggregateStats.cacheIcpPktsRecv
Note that the SNMP counter includes both queries and responses that your Squid cache receives. There is no SNMP object that will give you only the queries. You can get only received queries from the cache manager, however. For example:
# squidclient mgr:counters | grep icp.queries_recv
icp.queries_recv = 8595602You should normally expect to see a small number of denied requests as Squid operates. However, a high rate or percentage of denied requests indicates either 1) a mistake in your access control rules, 2) a misconfiguration on the cache client, or 3) someone attempting to attack your server.
If you use very specific address-based access controls, you'll need to carefully track IP address changes on your cache clients. For example, you may have a list of neighbor cache IP addresses. If one of those neighbors gets a new IP address, and doesn't tell you, all of its requests will be refused.
Unfortunately, there is no way to easily get a running total of denied
requests from either SNMP or the cache manager. If you want to track this
metric, you'll have to write a little bit of code to extract it from either the
cache manager client_list page, or from Squid's access.log
file.
The client_list page has counters for each client's ICP and HTTP
request history. It looks like this:
Address: xxx.xxx.xxx.xxx
Name: xxx.xxx.xxx.xxx
Currently established connections: 0
ICP Requests 776
UDP_HIT 9 1%
UDP_MISS 615 79%
UDP_MISS_NOFETCH 152 20%
HTTP Requests 448
TCP_HIT 1 0%
TCP_MISS 201 45%
TCP_REFRESH_HIT 2 0%
TCP_IMS_HIT 1 0%
TCP_DENIED 243 54%With a little bit of Perl, you can develop a script that prints out IP
addresses of clients having more than a certain number or percentage of
TCP_DENIED or UDP_DENIED requests. The primary problem
with using this information is that Squid never resets the counters. Thus, the
values are not sensitive to short-term variations. If Squid has been running for
days or weeks, it may take a while until the denied counters exceed your
threshold. To get more immediate feedback, you may want to search for
UDP_DENIED and TCP_DENIED in your access.log
file and count the number of such requests.
The HTTP service time represents how long it usually takes to complete a single HTTP transaction. In other words, it is the amount of time elapsed between reading the client's request and writing the last chunk of the response. Response times generally have heavy-tailed distributions, so we use the median as a good indicator of the average.
In most situations, the median service time should be between 100 and 500 milliseconds. The value that you actually see may depend on the speed of your Internet connection and other factors. Of course, the value varies throughout the day, as well. You'll need to collect this metric for a while to understand what is normal for your installation. A service time that seems too high may indicate that 1) your upstream ISP is congested, or 2) your own Squid cache is overloaded or suffering from resource exhaustion (memory, file descriptors, CPU, etc.). If you suspect the latter, simply look at the other metrics described here for confirmation.
To get the five-minute median service time for all HTTP requests, use this SNMP OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.cacheMedianSvcEntry.cacheHttpAllSvcTime.5
By browsing the MIB, you can find separate measurements for cache hits, cache misses, and 304 (Not Modified) replies. To get the median HTTP service time from the cache manager, do this:
# squidclient mgr:5min | grep client_http.all_median_svc_time
client_http.all_median_svc_time = 0.127833 secondsYou can also use the high_response_time_warning directive in
squid.conf to warn you if the response time exceeds a pre-defined
threshold. For example:
high_response_time_warning 700The DNS service time is a similar metric, although it measures only the amount of time necessary to resolve DNS cache misses. The HTTP service time measurements actually include the DNS resolution time. However, since Squid's DNS cache usually has a high hit ratio, most HTTP requests do not require a time-consuming DNS resolution.
A high DNS service time usually indicates a problem with Squid's primary DNS server. Thus, if you see a large median DNS response time, you should look for problems on the DNS server, rather than Squid. If you cannot fix the problem, you may want to select a different primary DNS resolver for Squid, or perhaps run a dedicated resolver on the same host as Squid.
To get the five-minute median DNS service time from SNMP, request this OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.cacheMedianSvcEntry.cacheDnsSvcTime.5
And from the cache manger:
# squidclient mgr:5min | grep dns.median_svc_time
dns.median_svc_time = 0.058152 secondsFile descriptors are one of the finite resources used by Squid. If you don't know how critical file descriptor limits are to Squid's performance, read the first section of Six Things First-Time Squid Administrators Should Know and/or Chapter 3 of Squid: The Definitive Guide.
When you monitor Squid's file descriptor usage, you'll probably find that it is intricately linked to the HTTP connection rate and HTTP service time. An increase in service time or connection rate also results in an increase in file descriptor usage. Nonetheless, it is a good idea to keep track of this metric, as well. For example, if you graph file descriptor usage over time and see a plateau, your file descriptor limit is probably not high enough.
Squid's SNMP MIB doesn't have an OID for the number of currently open file descriptors. However, it can report the number of unused (closed) descriptors. You can either subtract that value from the known limit, or simply monitor the unused number. The OID is:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheCurrentUnusedFDescrCnt
To get the number of used (open) file descriptors from the cache manger, search for this line in the "info" page:
# squidclient mgr:info | grep 'Number of file desc currently in use'
Number of file desc currently in use: 88Squid's CPU usage depends on a wide variety of factors including your hardware, features that you have enabled, your cache size, HTTP and ICP query rates, and others. Furthermore, high CPU usage is not necessarily a bad thing. All other things being equal, it is better to have high CPU usage and a high request rate than low CPU usage and a low request rate. In other words, after removing a disk I/O bottleneck, you may notice that Squid's CPU usage goes up, rather than down. This is good, because it means Squid is handling more requests in the same amount of time.
There are two things to watch for in the CPU usage data. First, any periods
of 100 percent CPU usage indicate some kind of problem, perhaps a software bug.
Henrik Nordstrom recently uncovered an incompatibly on Linux 2.2 kernels when
using poll() while half_closed_clients is enabled.
This Linux kernel bug can cause periods of 100 percent CPU utilization. As a
workaround you can disable the half_closed_clients directive.
The second reason to watch the CPU usage is simply to make sure that your CPU does not become a bottleneck. This might happen if you utilize CPU-intensive features such as Cache-Digests, CARP, or large regular expression-based access control lists. If you see Squid approaching 75 percent CPU utilization, you might want to consider a hardware upgrade.
Squid's SNMP MIB provides a CPU usage value with this OID:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheCpuUsage
Unfortunately, it is simply the ratio of CPU time to actual time since the process started. This means that it won't show short-term changes in CPU usage. To get more accurate measurements, you should use the cache manager:
# squidclient mgr:5min | grep cpu_usage
cpu_usage = 1.711396%Disk space is another finite resource consumed by Squid. When you run Squid on a dedicated system, controlling the disk usage is relatively easy. If you have other applications using the same partitions as Squid, you need to be a little more careful. We need to worry about disk space for two reasons: the disk cache and Squid's log files.
If Squid gets a "no space left on device" error while writing to the disk cache, it resets the cache size and keeps going. In other words, this is a non-fatal error. The new cache size is set to what Squid believes is the current size. This also causes Squid to start removing existing objects to make room for new ones. Running out of space when writing a logfile, however, is a fatal error. The Squid process exits, rather than continue operating without the ability to log important information.
Free disk space information is only available through the cache manager.
Furthermore, Squid only tells you about the cache_dir directories.
It won't tell you about the status of the partition where you store your log
files (unless that partition is also a cache directory). Thus, you may want to
develop your own simple script to monitor free space on your logging
partition.
The storedir cache manager page has a section like this for each
cache directory:
Store Directory #0 (diskd): /cache0/Cache
FS Block Size 1024 Bytes
First level subdirectories: 16
Second level subdirectories: 64
Maximum Size: 15360000 KB
Current Size: 13823540 KB
Percent Used: 90.00%
Filemap bits in use: 774113 of 2097152 (37%)
Filesystem Space in use: 14019955/17370434 KB (81%)
Filesystem Inodes in use: 774981/4340990 (18%)
Flags:
Pending operations: 0
Removal policy: lru
LRU reference age: 22.46 daysWe are particularly interested in two lines: the "Percent Used" and "Filesystem Space in use" lines.
The "Percent Used" line shows how much space Squid has used, compared to the
size you specified on the cache_dir line. This will normally be
equal to, or less than, the value for cache_swap_low.
The "Filesystem Space in use" line shows how much space is actually used on
this partition. Squid gets the information from the statvfs()
system call. It should match what you would see by running df from
your shell. This is the important value to watch. If the percentage hits 100
percent, Squid will receive "no space left on device" errors.
Cache hit ratio is another metric that can vary a lot from time to time. Its
high variability means that it is not always a good indicator of a problem. A
sudden drop in hit ratio might mean that one of the cache clients is a crawler
or something that adds no-cache directives to its requests. Perhaps
the best reason to monitor it is simply to understand how many requests benefit
are served directly from the cache (in case the boss asks you to justify Squid's
existence).
You can get the hit ratio, calculated over the last five minutes, by requesting this SNMP OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.cacheMedianSvcEntry.cacheRequestHitRatio.5
The same information is available on the cache manager "info" page:
# squidclient mgr:info | grep 'Request Hit Ratios'
Request Hit Ratios: 5min: 29.8%, 60min: 44.1%For better or worse, the cache manager currently provides more useful
information than Squid's SNMP implementation. However, the cache manager output
was designed to be human-readable. It would be awkward for you to write a bunch
of software to grep for all of the relevant information and extract
the values. Especially since I have already done it for you.
I have a Perl script, recently enhanced by Dan Kogai, to issue cache manager requests and store the values into an RRD database. If you don't know about RRDtool yet, you should. It is Tobi Oetiker's successor to MRTG. It's very cool.
My Perl script runs periodically from cron. It makes cache
manager requests and uses regular expressions to parse the output for certain
metrics. The extracted values are stored in various RRD files. I also provide a
template CGI script that displays the RRD data.
You can find my code and documentation at http://www.squid-cache.org/~wessels/squid-rrd/. I've included some of the graphs below. You can view more graphs (and look at the full-size versions of the ones below) by visiting my stats page for the IRCache proxies at http://www.ircache.net/Cache/Statistics/Vitals/rrd/cgi/.
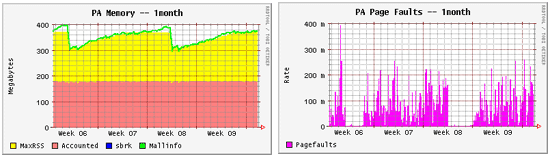
These two graphs show memory usage and page-fault rate for a
one-month period. You can clearly see when Squid was restarted because the
memory usage goes down. It slowly climbs back up as Squid runs. You can also see
that the page-fault rate increases as the memory consumption increases.

These five graphs show various metrics for a 24-hour period.
You can see that an increase in load causes corresponding increases in CPU
usage, file descriptor usage, and, to some extent, response times. The file
descriptor graph shows a brief spike during the late evening hours.
Duane Wessels discovered Unix and the Internet as an undergraduate student studying physics at Washington State University.
O'Reilly & Associates published Squid: The Definitive Guide in January 2004.
Chapter 8, "Advanced Disk Cache Topics," is available free online.
You can also look at the Table of Contents, the Index, and the full description of the book.
For more information, or to order the book, click here.
Return to ONLamp.com.
Copyright © 2004 O'Reilly Media, Inc.